
首先,使用Nofollow标签是一种较为直接的方法通过在链接上添加Nofollow属性,搜索引擎会忽略该链接的权重传递,从而避免重复内容被过度强调然而,这种方法的缺点在于操作相对繁琐,需要对网页中的每个链接进行检查并添加标签其次,Robotstxt文件是网站管理员用来控制搜索引擎爬虫访问的工具通过在Robots。
Robots协议还支持其他一些特殊参数,如Googlebot的处理规则,以及Allow和Disallow的混合使用另外,robotstxt文件虽古老,但各大搜索引擎对其解读可能有差异,建议使用搜索引擎提供的工具进行验证在个别页面上,可以使用Robots Meta标签提供更具体的抓取指令,如indexnoindexfollow和nofollow,但这并不像。
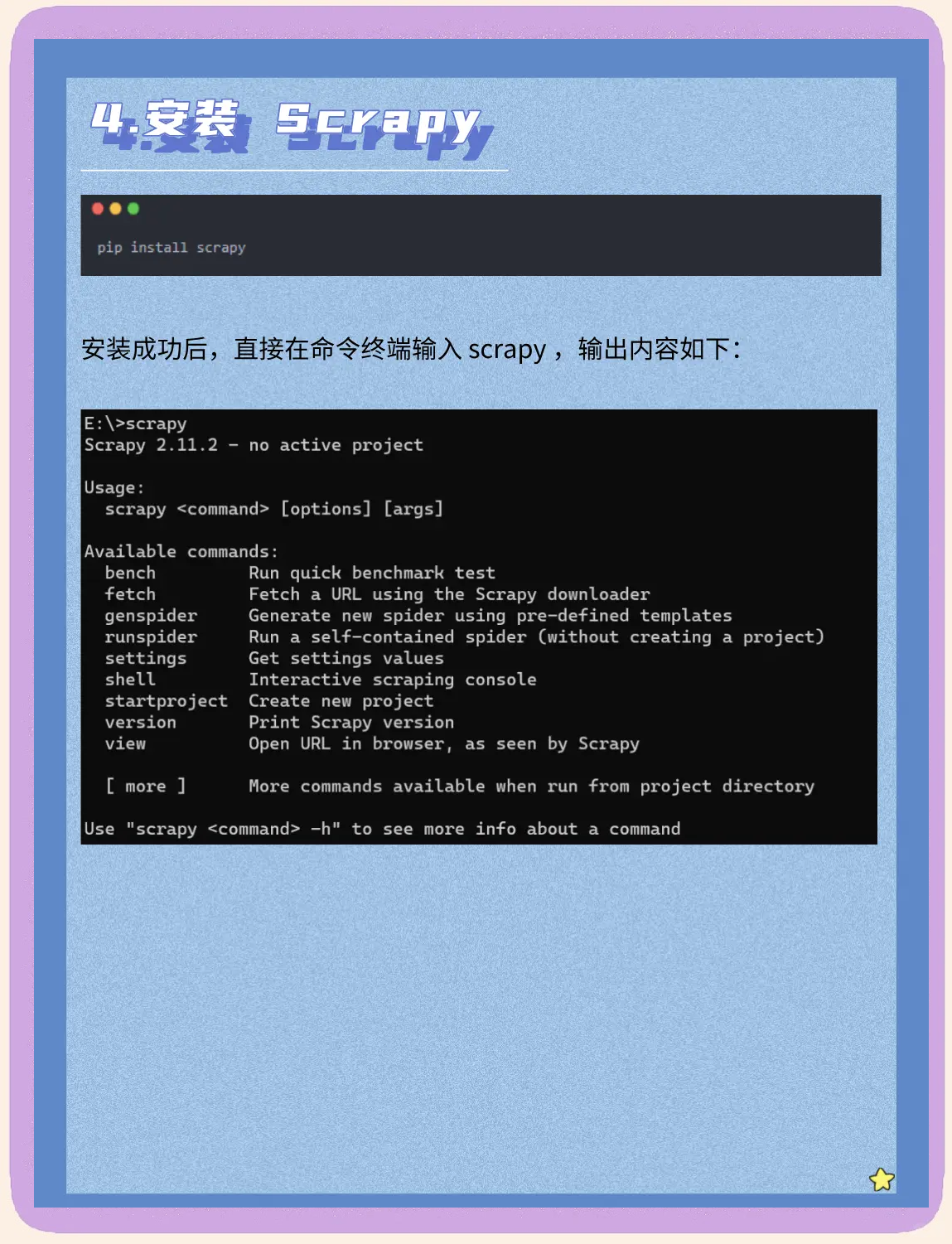
确保robotstxt文件未阻碍爬虫抓取检查robotstxt文件,移除阻碍Googlebot抓取的“Disallow”规则去除noindex标签确保网页中未设置noindex meta标签或XRobotsTag,使用网站诊断工具检测并删除添加至网站地图将需要索引的页面包含在网站地图中,并使用ping方法通知Google修复ca。
详细信息可以参考Google支持的元标记,这里提一句noindex和nofollow在 HTML401规范 里有描述,但是其他tag的在不同引擎支持到什么程度各不相同,还请读者自行查阅各个引擎的说明文档 Crawldelay 除了控制哪些可以抓哪些不能抓之外,robotstxt还可以用来控制爬虫抓取的速率如何做到的呢?通过设置爬虫在两次抓取之间。
转载请注明来自中国金属学会,本文标题:《seo爬虫如何处理robots.txt文件和nofollow标签》
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...